


This is a qualitative analysis and evaluation of the performance of the industry’s four leading AI models, ChatGPT, Grok, Gemini, and Claude.
The objective was not only to identify which tools perform best, but to surface practical prompting strategies and operational insights for teams working at the intersection of science, data, and digital content.
A critical lens in this evaluation is recognizing that “model performance” is not a fixed attribute—it is highly dependent on access. Capabilities can vary significantly based on subscription tier, token limits, and available tools. While enterprise versions of these platforms offer expansive context windows, advanced file handling, and multimodal capabilities, free and lower-tier versions are often constrained by tighter limits on inputs, outputs, and integrations. These differences directly impact how effectively each model can support complex scientific content workflows.
In addition to performance benchmarking, we reviewed how these structural differences influence real-world usability—from large-scale document analysis and code generation to handling scientific imagery and integrating external data. The result is a more practical view of AI adoption in life sciences: not just which model is “best,” but which configuration is fit for purpose.
Performance Overview
Across all prompting categories, Grok consistently achieved the highest scores in prompts that were focused on research and analytical tasks. It excelled specifically in summarization and data analysis, indicating a strong capacity in synthesizing datasets and then providing conclusions for such complex information. Its mathematical capabilities render it an effective tool for prompts that require extreme depth, and experimentation revealed that it rarely suffered from hallucinations and was well-suited for insightful and competitive generated life science responses. However, its response times significantly varied, with smaller prompts averaging around fifteen to thirty seconds, and more complex prompts being generated after sixty to above ninety seconds. Such limitations diminish its choice as the rapid tool, but its strengths label it the most effective for data analysis and strategic calculations.
ChatGPT was a stand out in its ability to respond to a diverse range of prompts, regardless of their content. Its efficiency was demonstrated in its rapid response time and ability to quickly summarize data, as well as analyze it. Additionally, one of its major strengths is its ability to interpret various forms of information, ranging from documents to visual stimulants, rendering it the best tool for prompts that require context that originates from non-textual sources. Despite these strengths, the AI model struggled in high-complexity scientific synthesis relative to its counterparts. It also frequently experienced hallucinations and complications with superficial analysis, as well as drift when inputting multiple responses. It is the most optimal for rapid response generation, but not the most efficient for complex data analysis.
Gemini experienced a balanced performance across creative and scientific-oriented prompts. Its strengths were demonstrated in the ability to generate ideas, research news articles, and detect bias within datasets. However, its accessibility and function is severely limited by its reliance on Google products, such as Gmail. A majority of its ability to synthesize information and analyze data is based on information from its parent company’s search engine, meaning it is effective in organizing and scheduling calendar events but not for complex life science prompts. It acts as a middle-ground, between the necessity of deep and insightful response and integration within commonly utilized services and domains. Ultimately, its strengths rely in its discoverability of information across search engines and its optimization in adapting to the user’s tasks, but it falls short in relation to its ability to endure complex scientific prompting.
Claude demonstrated superior performance in editing, structuring, and other tasks that required refinement or optimization. Its strengths are based on its ability to consistently generate similar responses to prompts, regardless of the dataset provided. It succeeded in complex data analysis, as well as interpreting audio and visual sources, rendering it the most effective tool for polishing content development and executing deliverables. However, its flaws regarding its own accessibility and response time are significant. While not suffering from hallucinations or superficiality, the AI model consistently required context before responding to prompts, which delayed its response times and caused complications for the user. It forces the user to adapt to its own preferred style of prompting, rendering it practical for corporations or enterprises, but not for individual users.
Chart 1:
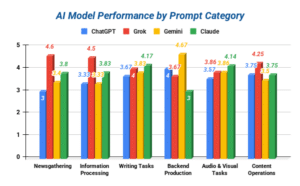
Chart Key:
| 5 | Output was accurate and nuanced, requiring minimal editing. |
| 4 | Output was strong and scientifically solid, requiring minor corrections. |
| 3 | Output was adequate, but may be too generic or lacks precision. |
| 2 | Output was weak and suffers from multiple inaccuracies. |
| 1 | Output was unreliable and demonstrated symptoms of hallucinations. |
Key Insights
- No Single AI Model Dominates All Tasks
- Each tool demonstrated specialized strengths. It is strongly advised against employing one model for an entire workflow as this can lead to suboptimal outcomes.
- Research and Writing Support Tasks Is a Clear Divide
- AI agents that excelled at research, such as Grok, were not sufficient in writing refinement, such as where Claude leads. Separating prompts based on the type of AI model improves the quality of outputs and responses.
- Prompt Design Impacts Performance Variability
- Regardless of the quality of the model, vague and complex prompts tend to produce below-average responses. Structured and concise prompts consistently yield superior outputs.
- Content Operations Benefit from Specialization
- Tasks that require social transformation or PR pitching are more efficiently handled by models tuned for marketing outputs, such as Gemini, rather than research or analytical-focused tools.
- Quality Assurance Remains Critical
- Despite excellent performances, hallucinations and overgeneralizations persist in all AI agents, regardless of their quality. Validation steps such as human audit or review are essential to ensuring that the quality of outputs matches the necessary requirements.
Not All GenAI Models Are Created Equal
It is important to note that the capabilities and tools for each AI agent can significantly vary depending on the specific model, tier, and/or subscription the individual employs in its application. To stay up to date on constant updates being applied to these models, the best practice is to follow their respective developers and publishers on social media to keep up to date on updates, maintenance schedules, and upcoming features and tool implementation. As for a token, in general, tokens are typically four characters and serve as the building blocks for the models’ language processing when it generates a prompt. While all four of these AI agents have a specific enterprise/team model that allows for nearly unlimited utilization and over 128 thousand tokens, they also have their own respective tiers, subscriptions, capabilities, and individual tools that separate their function and niche:
| ChatGPT |
|
| Grok |
|
| Gemini |
|
| Claude |
|
Conclusion
The evaluation demonstrates that in order to produce life science content that is both high in quality and efficient, strategic prompt engineering and multi-model orchestration is significantly required. Grok stands out in analytical depth, ChatGPT for its velocity, Gemini for its accessibility, and Claude for its content refinement. Success is not determined solely by the model, but rather by how each tool, prompt, and workflow are integrated.
Organizations that successfully implement structured workflows, allowing for each AI model to be assigned to its area of strength, will significantly achieve higher content quality, efficiency, and a stronger impact and influence than those relying on a single AI system.
