
By Alex Lessing, 4th year Computational Social Science and CogSci at UCSD
Abstract
Current generative AI image models have the ability to remix and refine existing visualizations in the form of image-to-image generation. This can be applied to scientific data, such as microscope images of virions, to create unique variations and enhancements whilst preserving a certain degree of accuracy. Here, the output of three modern models were compared within the context of microscopic images, many of which achieved convincing realism. The models’ strengths and weaknesses were further evaluated with set criteria, making them relevant to different use cases.
Introduction
Despite their recent explosion in popularity, using neural networks to create images is not a new idea. It is likely fair to say that this approach received its first significant popularity through GANs (Generative Adversarial Networks) developed in 2014. This architecture combines two models: a discriminator being trained to detect real images, and a generator that continually improves by trying to outsmart the discriminator. This novel approach, acting as a zero-sum game, allowed for the development of models that could generate high quality – even photorealistic – images, particularly NVIDIA’s StyleGAN. Although this led to admiration worldwide, image generation AI was still largely ignored outside of enthusiast circles. It had limited conditioning capabilities, meaning there was no intuitive way to control outputs outside of the training process. This (combined with their general instability and struggle with multi-modal data) led to niche models that could only generate within a single domain, greatly restricting their usefulness to the general public.
This changed with the advent of high-fidelity Diffusion Models, such as DALL-E from OpenAI, as well as the subsequent open-source implementations, namely CompVis’s Latent Diffusion leading to the well-known Stable Diffusion by StabilityAI. Instead of the adversarial game seen in GANs, these models adopted a more stable approach: gradually forming images through an iterative denoising process. This technique was shown to scale better, allowing both the creation of higher quality images and the usage of more intricate conditioning, such as natural language prompts processed by a text encoder as well as complex reference images.
Understanding Image-to-Image in Diffusion Models
Modern prompt-based image generators operate using denoising, a process that involves iteratively converting arbitrary noise into an image that matches vectors obtained from training data. As a relatable analogy, this could loosely be compared to the common phenomenon of “seeing” personally relevant imagery in the random patterns of wood, marble, etc.
Figure 1. Diffusion Illustration

Starting with an initial image instead of complete noise causes the diffusion process to be guided by the characteristics of the reference image. By specifying the denoising strength, the amount of AI influence can be controlled. (Or conversely, how close the output will remain to the reference).
Methods
Three modern AI models were tested:
- Midjourney V6.1 by Midjourney, Inc.
Ran through the Discord interface with messages that contained the initial image, the prompt “electron microscope image of <subject>”, and the maximum image weight parameter 3 (–iw 3.0).
- FLUX.1-dev by Black Forest Labs
Ran on local computer through open-source interface ComfyUI, and same prompts as Midjourney. The initial image was passed to the model with VAE (Variational AutoEncoder) encoding, and the model denoise strength was tuned on a per-image basis for best results, with a range of 40%-85%.
- Playground V3 by Playground AI
Ran through implementation on Poe, attaching the reference images and using the same prompt as above.
Results
Each model was evaluated using various criteria. A table was used to summarize the results, with colors representing the models’ performance in a given area. As AI models are highly complex systems, most evaluations are subjective and imperfect. Here, the color ratings serve to estimate the models’ performance relative to each other. Explanations for the evaluations are below.
- Image-to-Image Control: How configurable the image-to-image process is, particularly the initial image strength.
a. Midjourney: the –iw command changes the reference strength, with acceptable values being 0.0-3.0 as of V 6.1. This offers decent control, but more similarity to the reference image may be desired beyond the maximum of 3.0, which cannot be achieved.
b. Local FLUX: Capable of a full denoise range of 0-100, where 100 is an entirely new image, and 0 is identical to the reference. (No denoising).
c. Playground V3 on Poe: No denoise parameter or equivalent. - User Interface and Intuitiveness: How easy it is to set up the tool and operate the UI.
a. Midjourney: Operates through the Discord app, which is a simple messaging system.
b. Local FLUX: A local interface is needed to run the model, as well as the weights. All components must be downloaded and configured on the user’s own computer. Additionally, powerful hardware is required.
c. Playground V3 on Poe: Simple chat interface, similar to Midjourney. - Visual Fidelity: The quality of the outputs.
a. All tools: High quality images are produced with no or very little visible artifacts. - Style Flexibility: The diversity of styles that can be produced with the model in a scientific context.
a. Midjourney: Faithful to the micrograph style, though the image weight parameter can be lowered if more deviation is desired.
b. Local FLUX: Micrograph style is quickly replaced by model’s own interpretation as denoise strength is increased, though image composition remains. Trial and error is needed to achieve desired results.
c. Playground V3 on Poe: Very repetitive images that comparatively lack distinct elements. - Price: How affordable it is to access the model.
a. Midjourney: $10/month for 200 images, $30/month for unlimited.
b. Local FLUX: Free, assuming adequate hardware.
c. Playground V3 on Poe: Limited free access, $20/month for increased limits.
🟢 = Best | 🟡 = Decent | 🔴 = Poorest
| Comparison | Midjourney | Local FLUX | Playground |
| Image-to-Image Control | 🟡 | 🟢 | 🔴 |
| User Interface & Intuitiveness | 🟢 | 🔴 | 🟢 |
| Visual Fidelity | 🟢 | 🟢 | 🟢 |
| Style Flexibility | 🟢 | 🟡 | 🔴 |
| Price | 🔴 | 🟢 | 🟡 |
Figure 2. Comparison Table
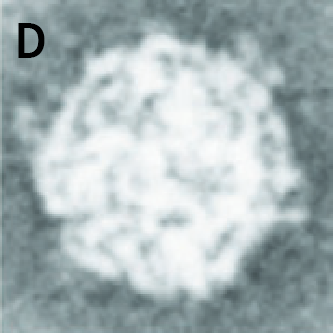
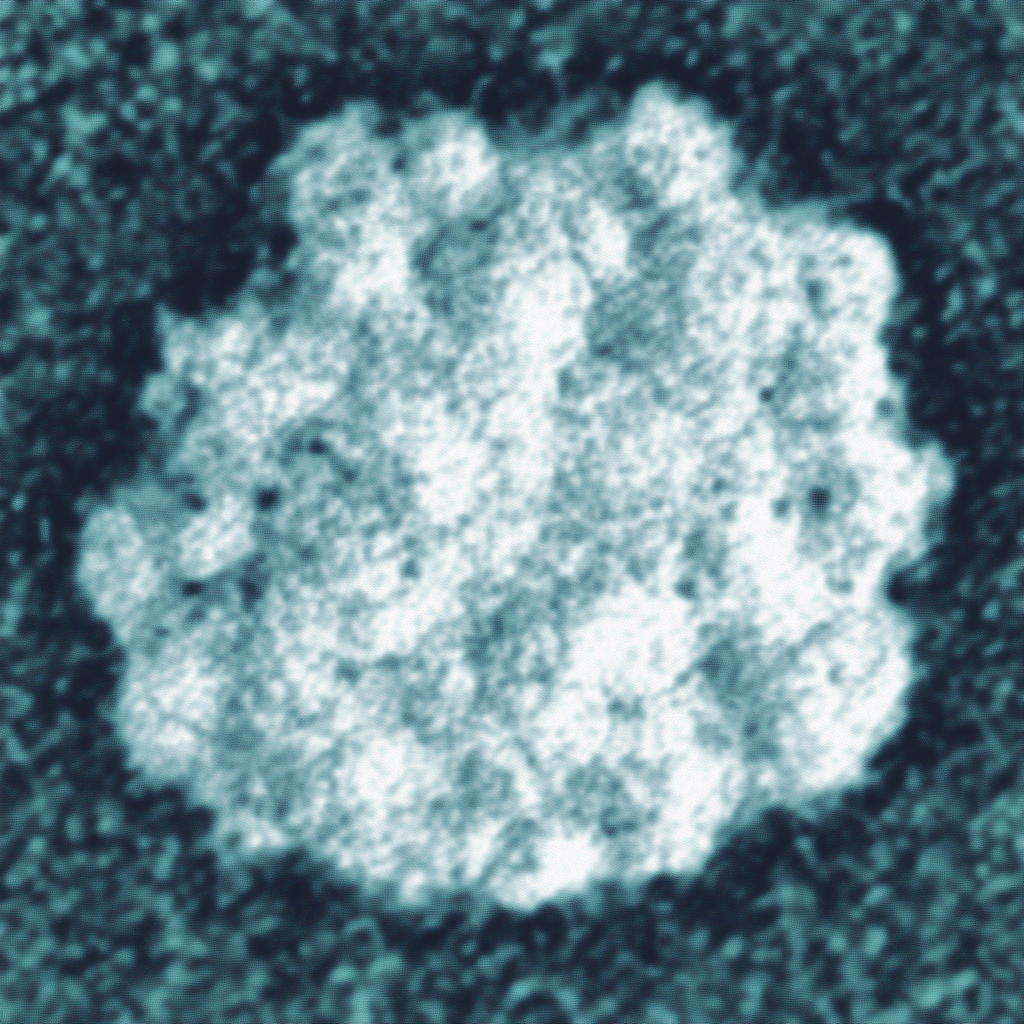
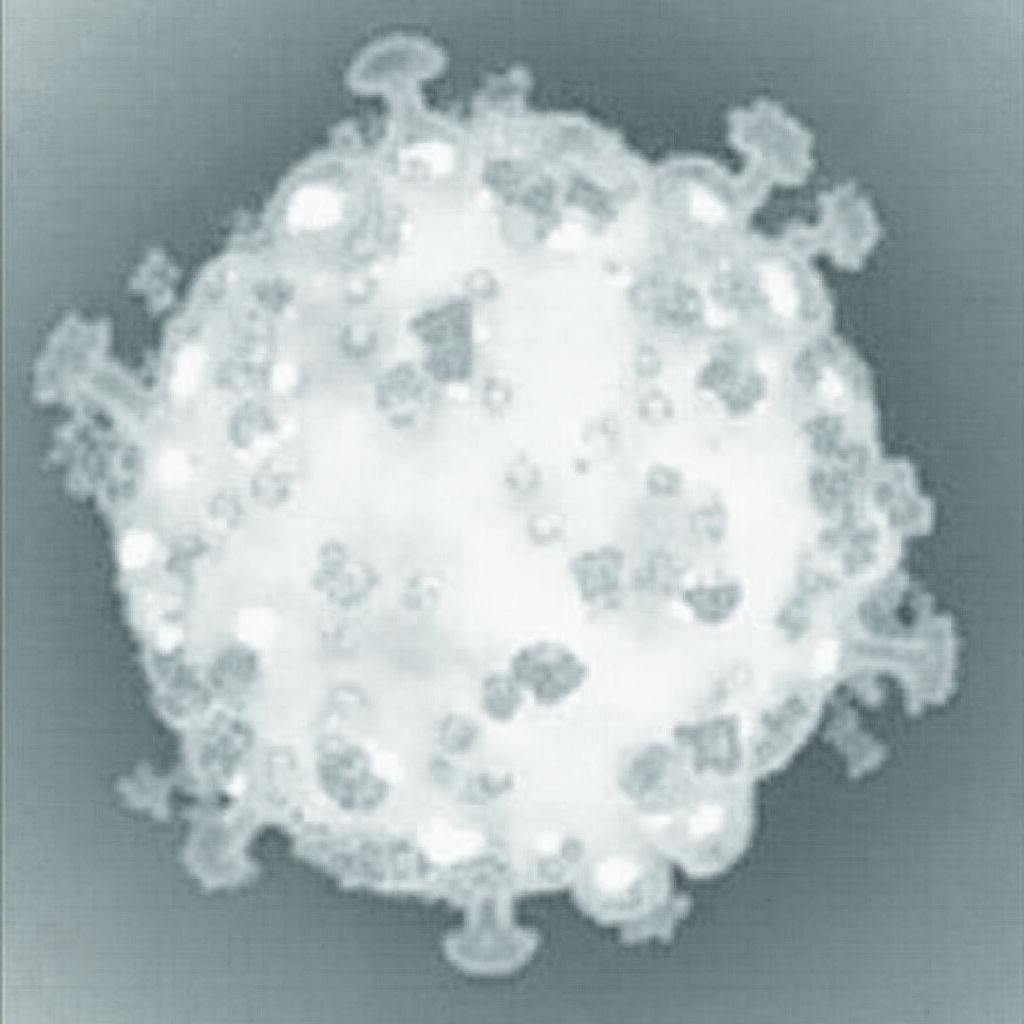
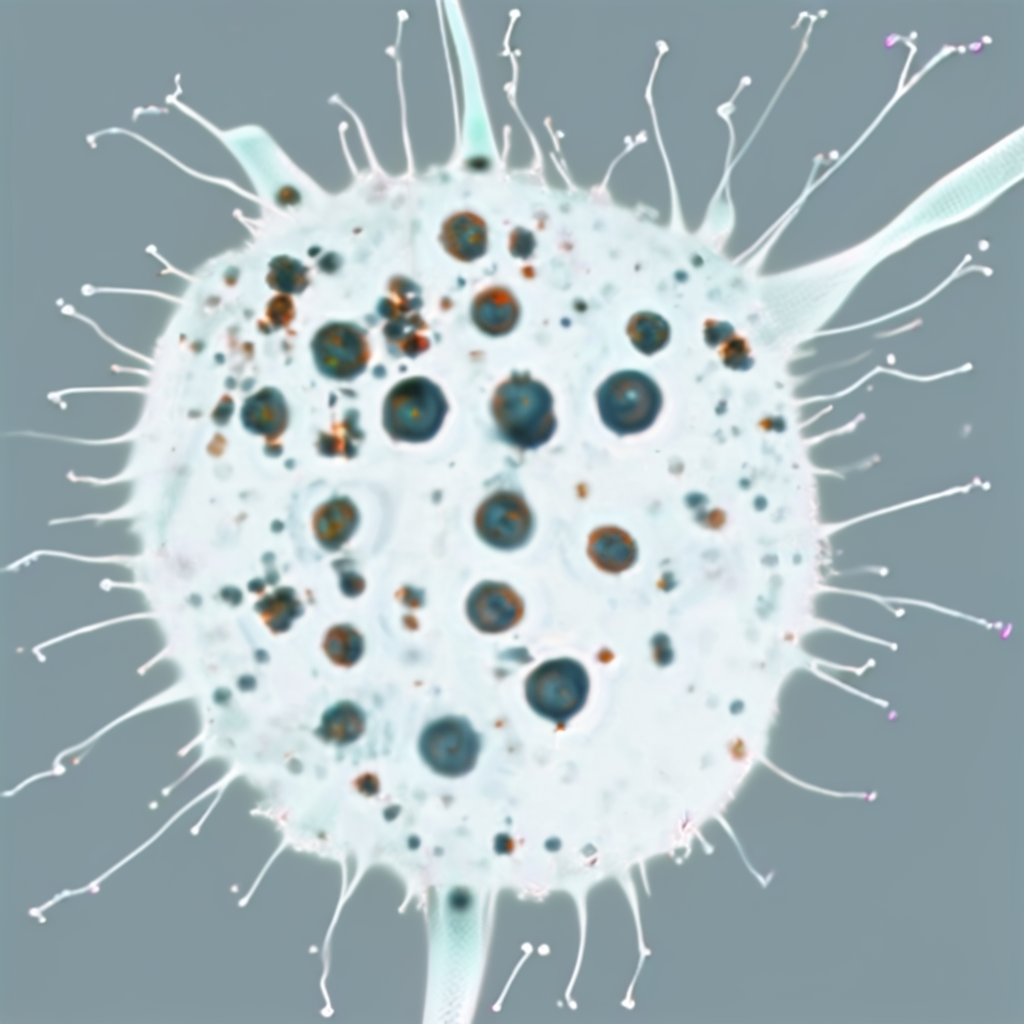
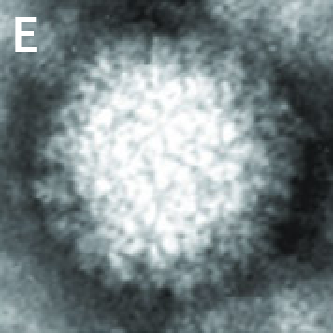
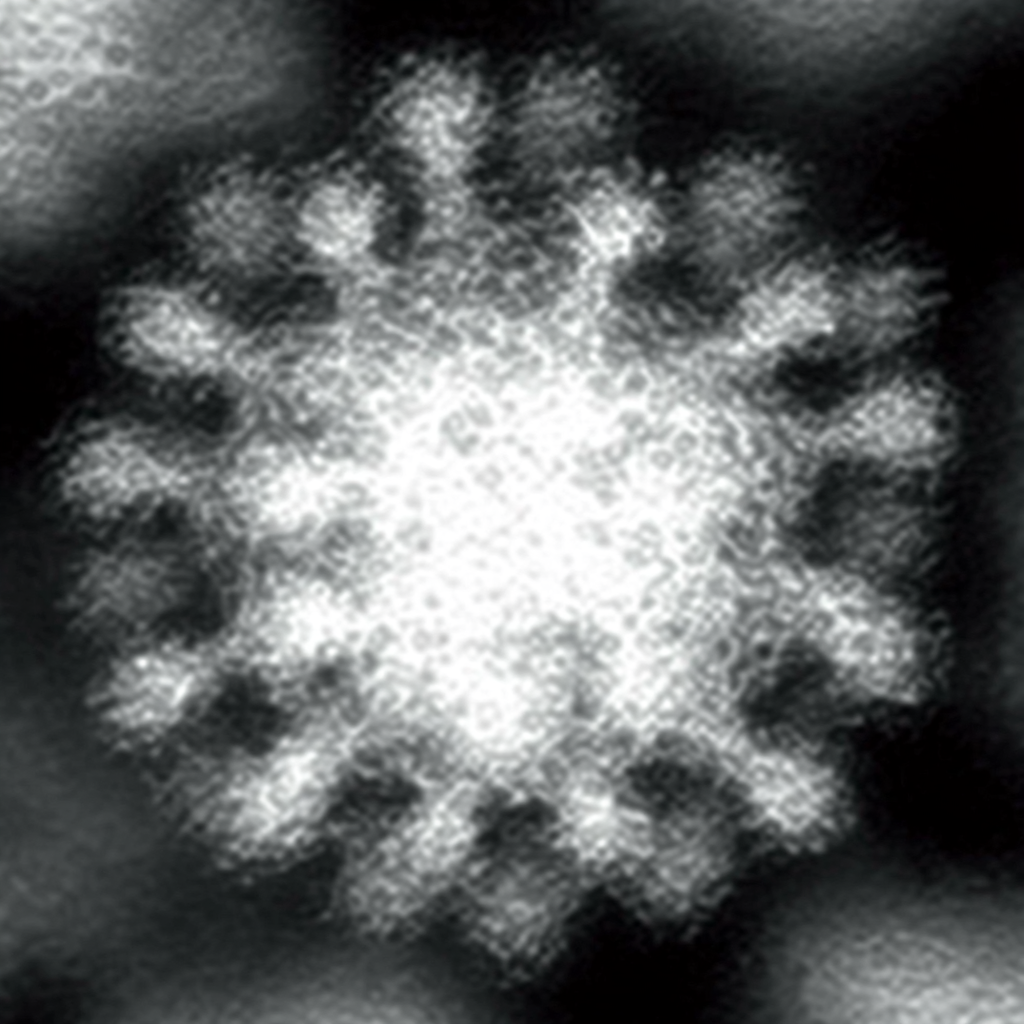
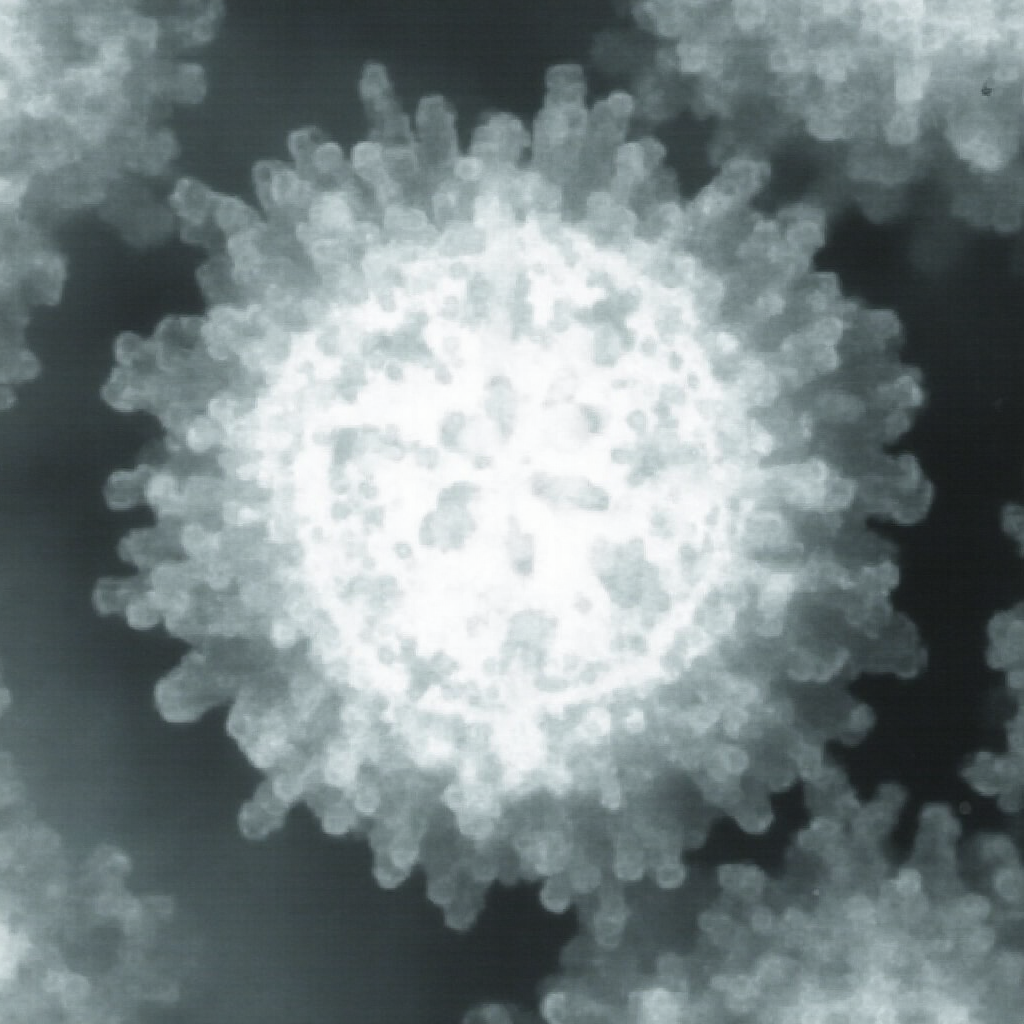
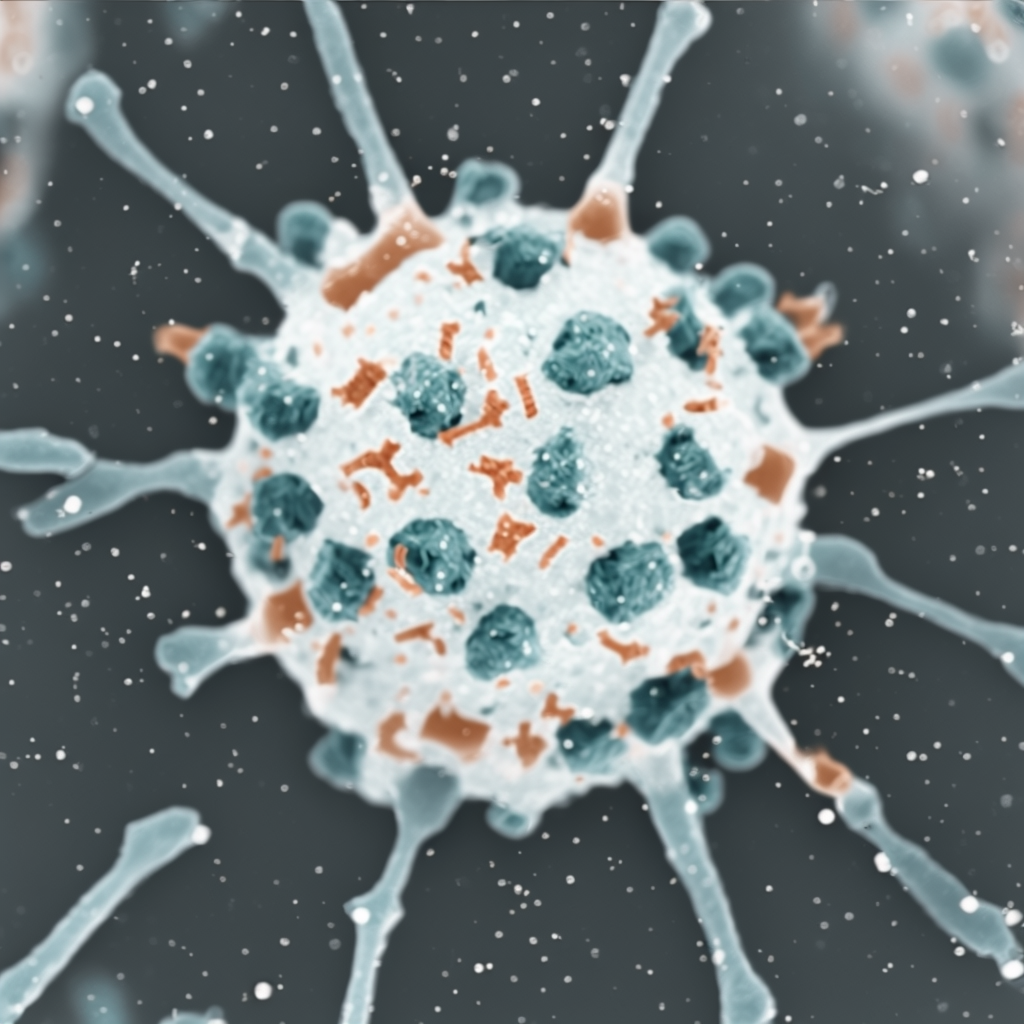
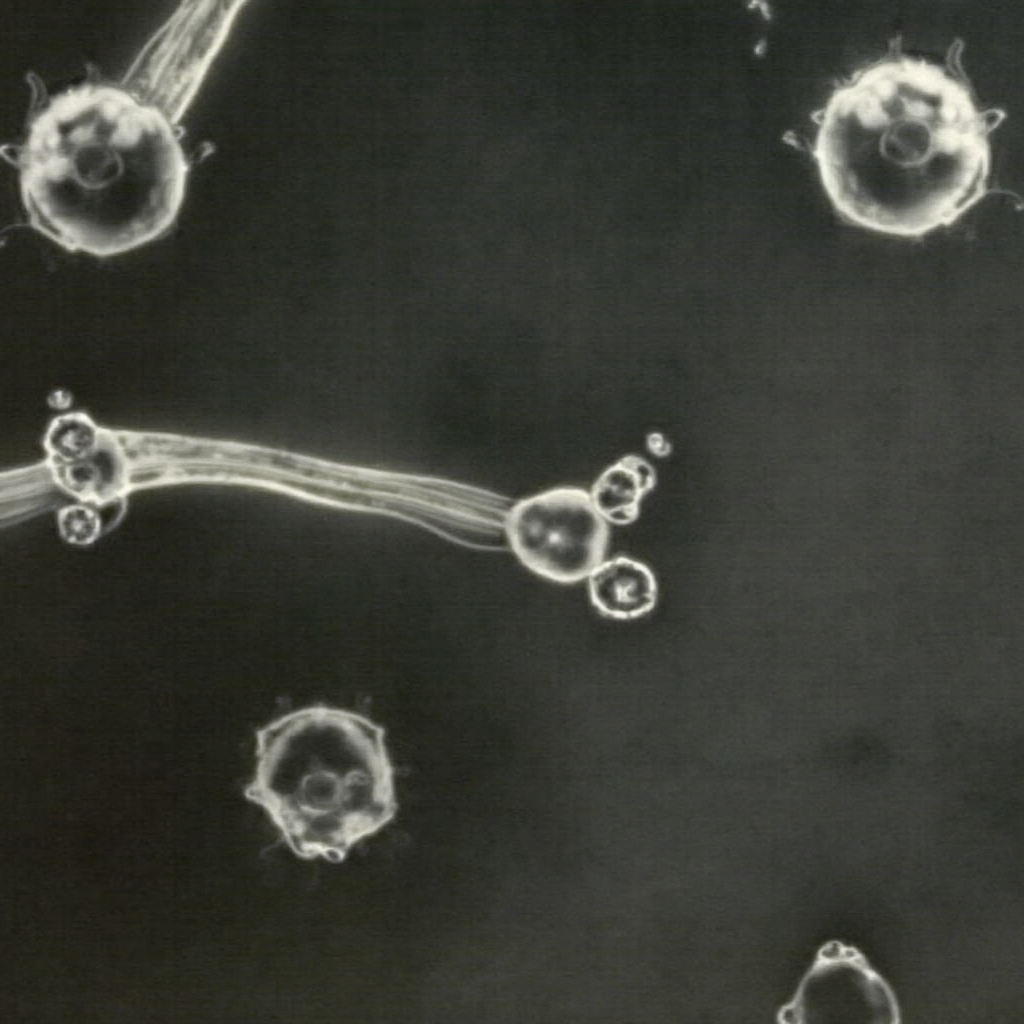
| Original Image | Midjourney v6.1 | FLUX.1-dev | Playground v3 |
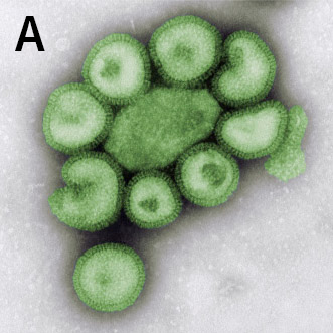 |
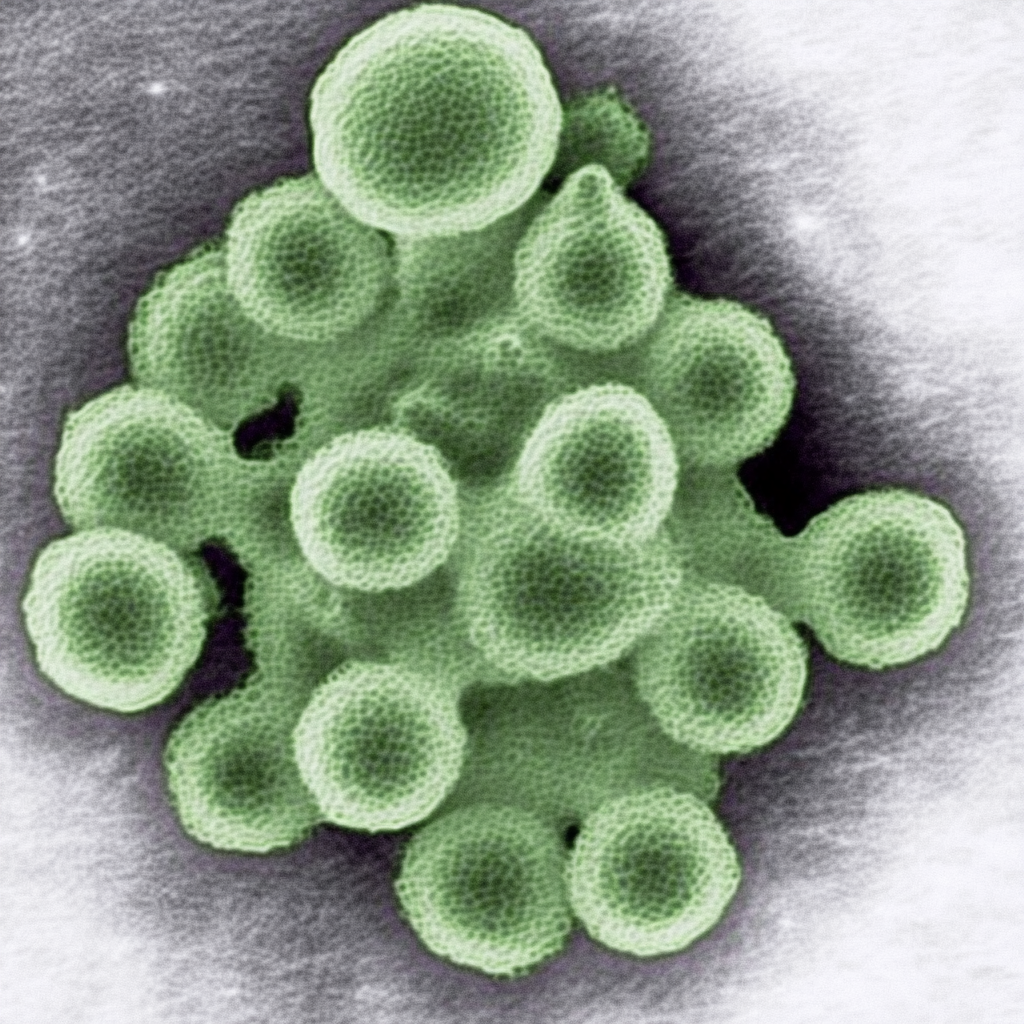 |
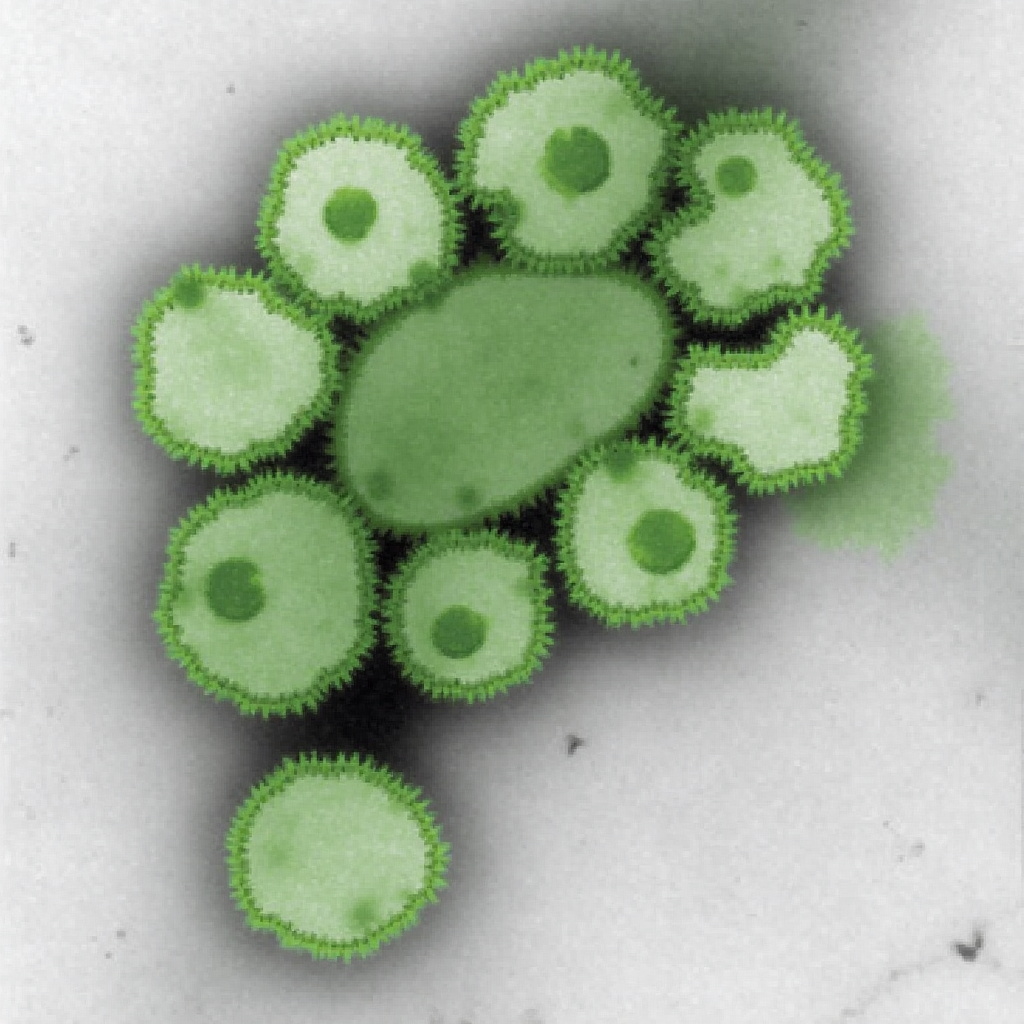 |
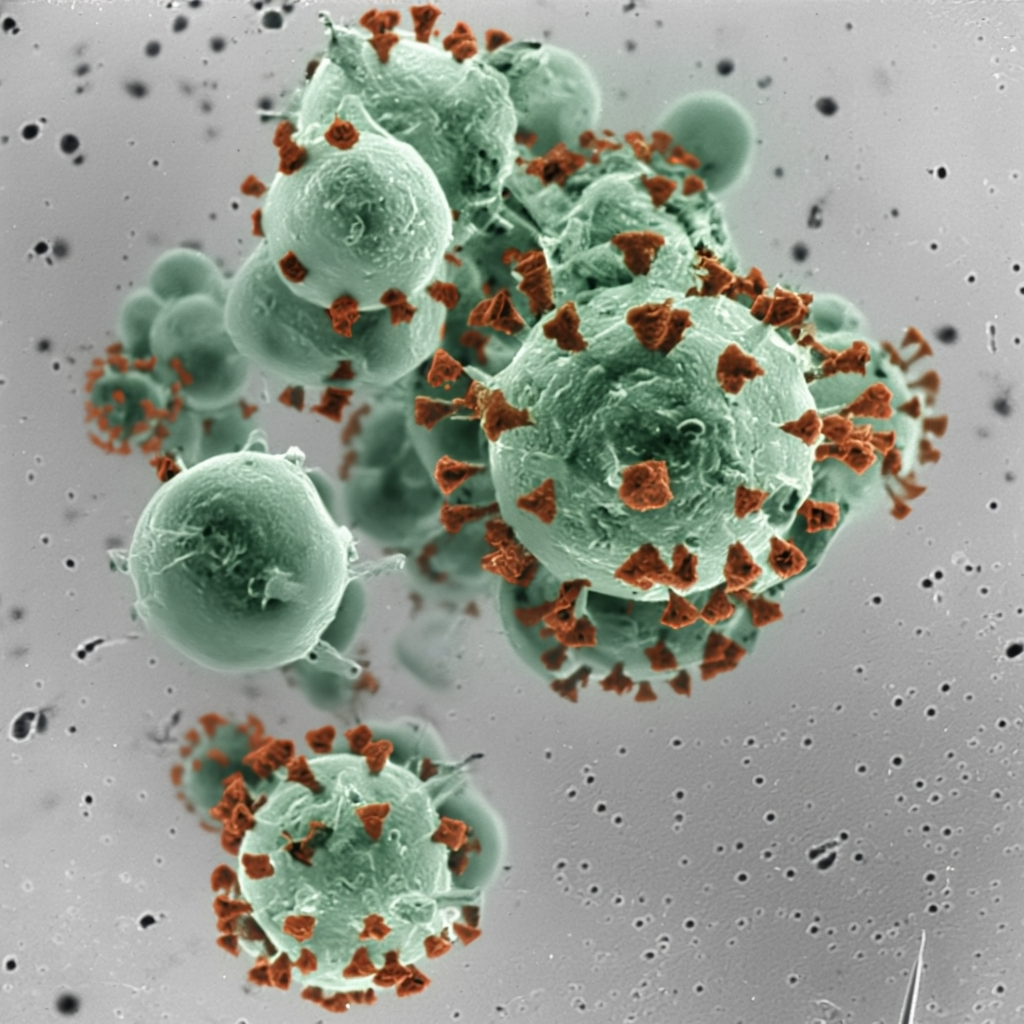 |
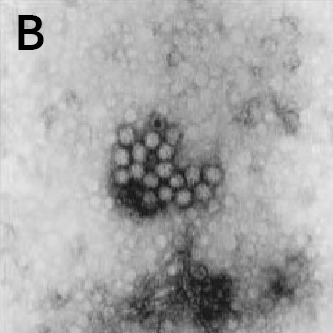 |
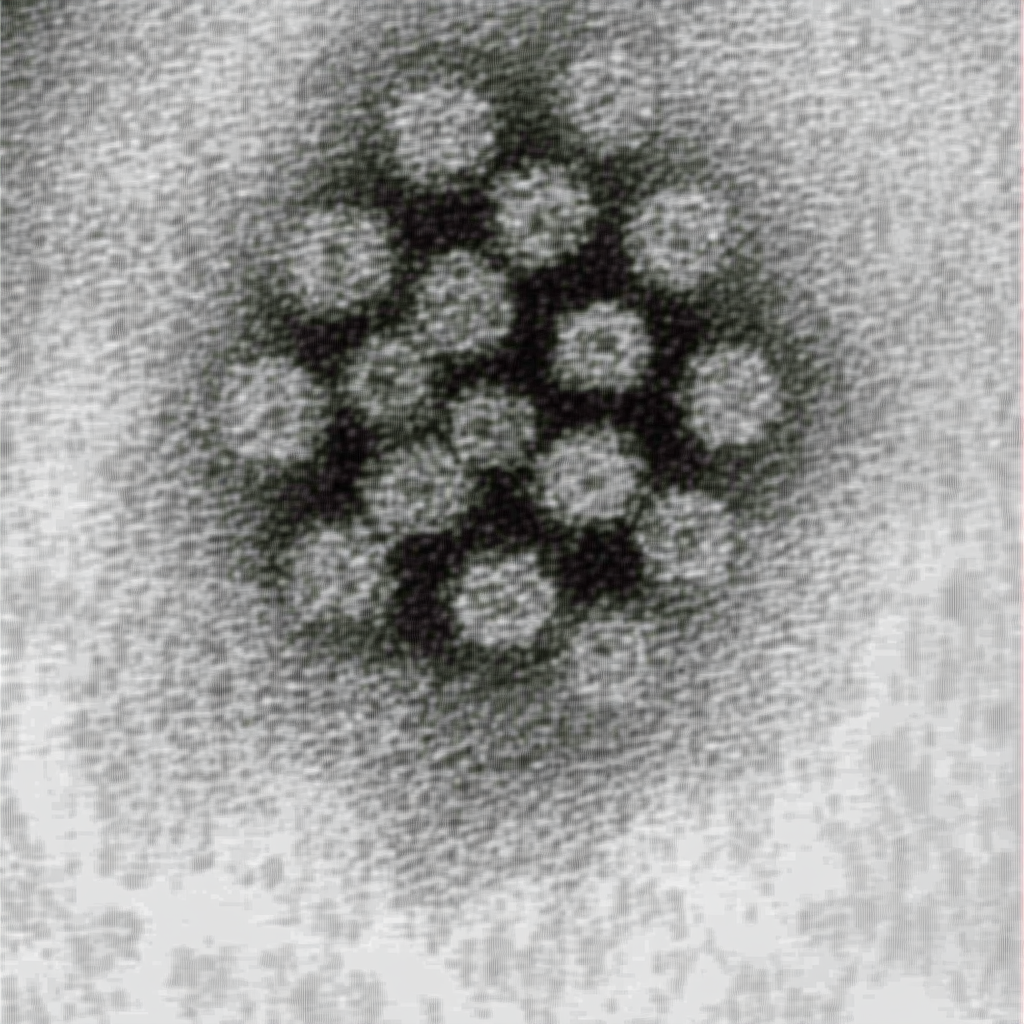 |
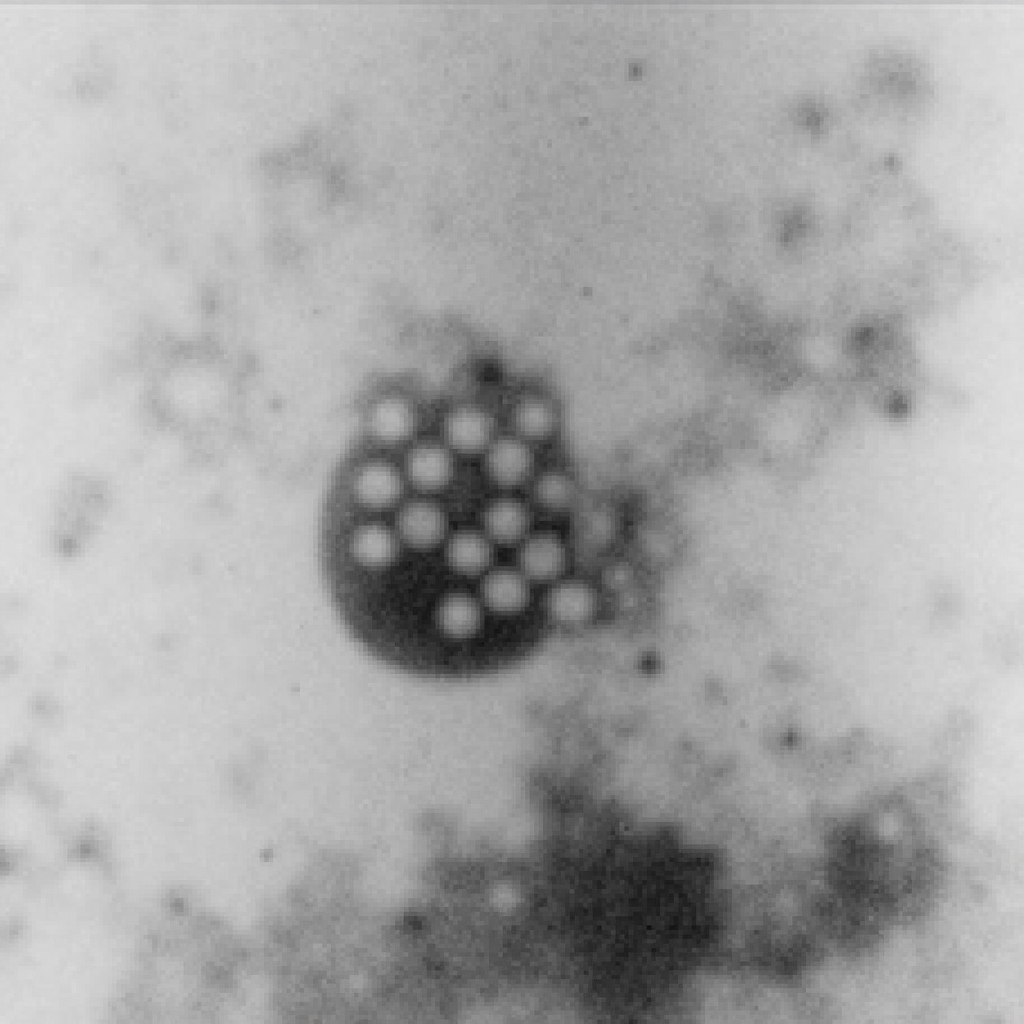 |
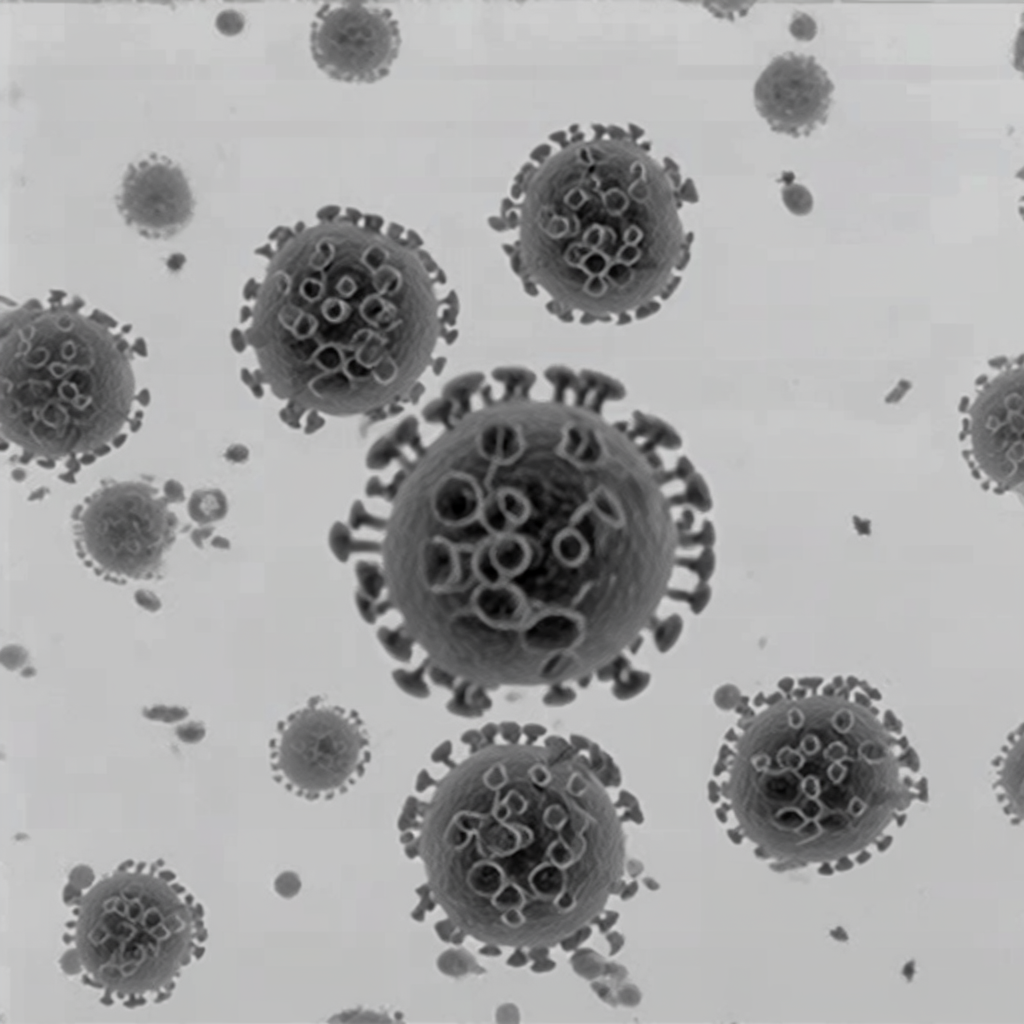 |
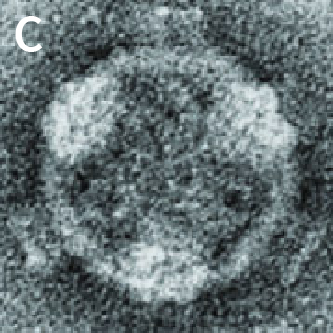 |
 |
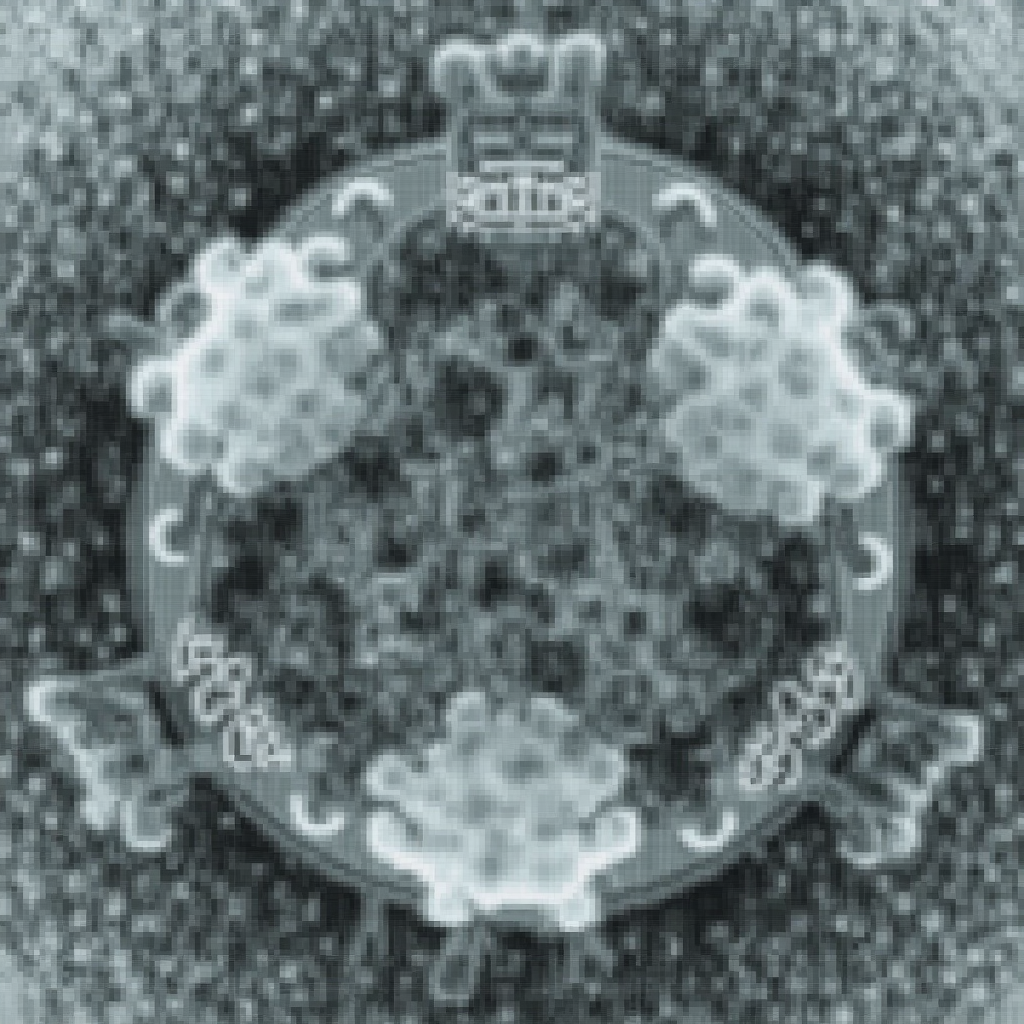 |
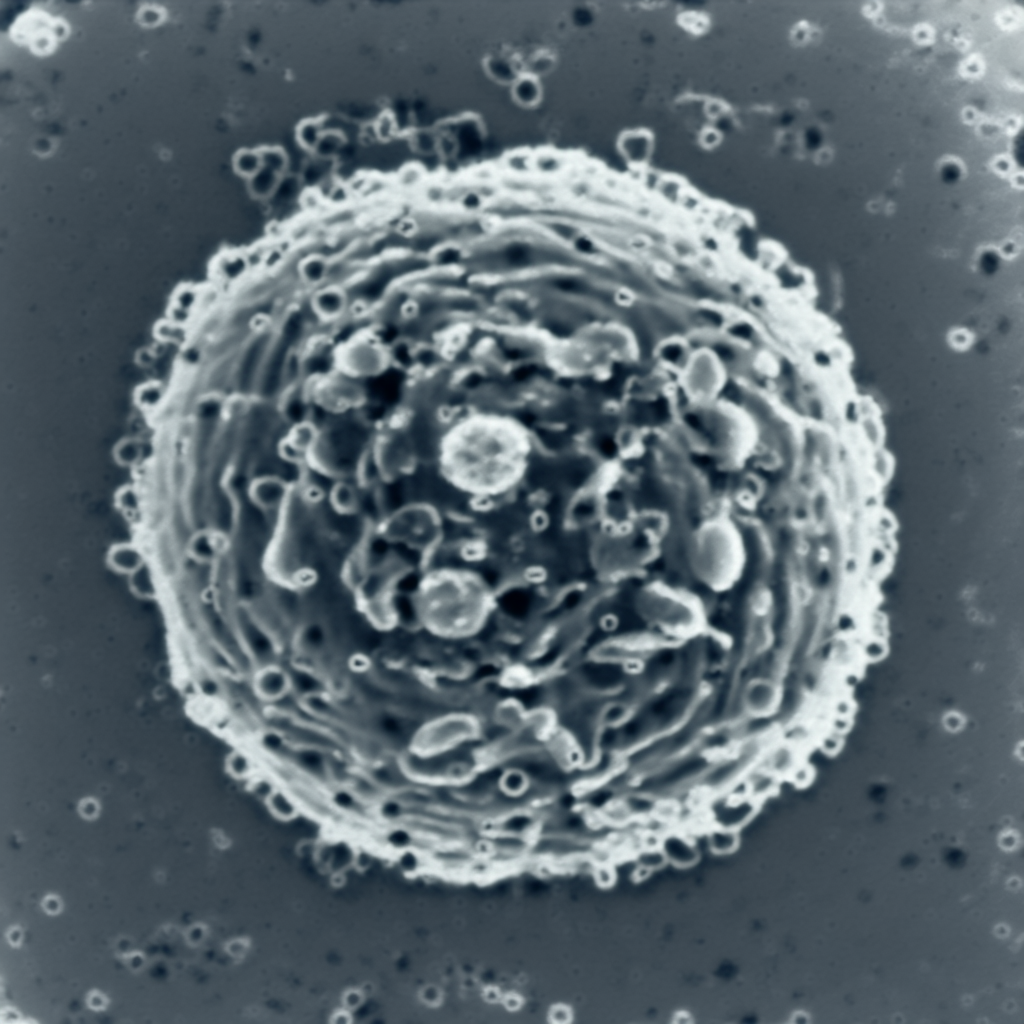 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
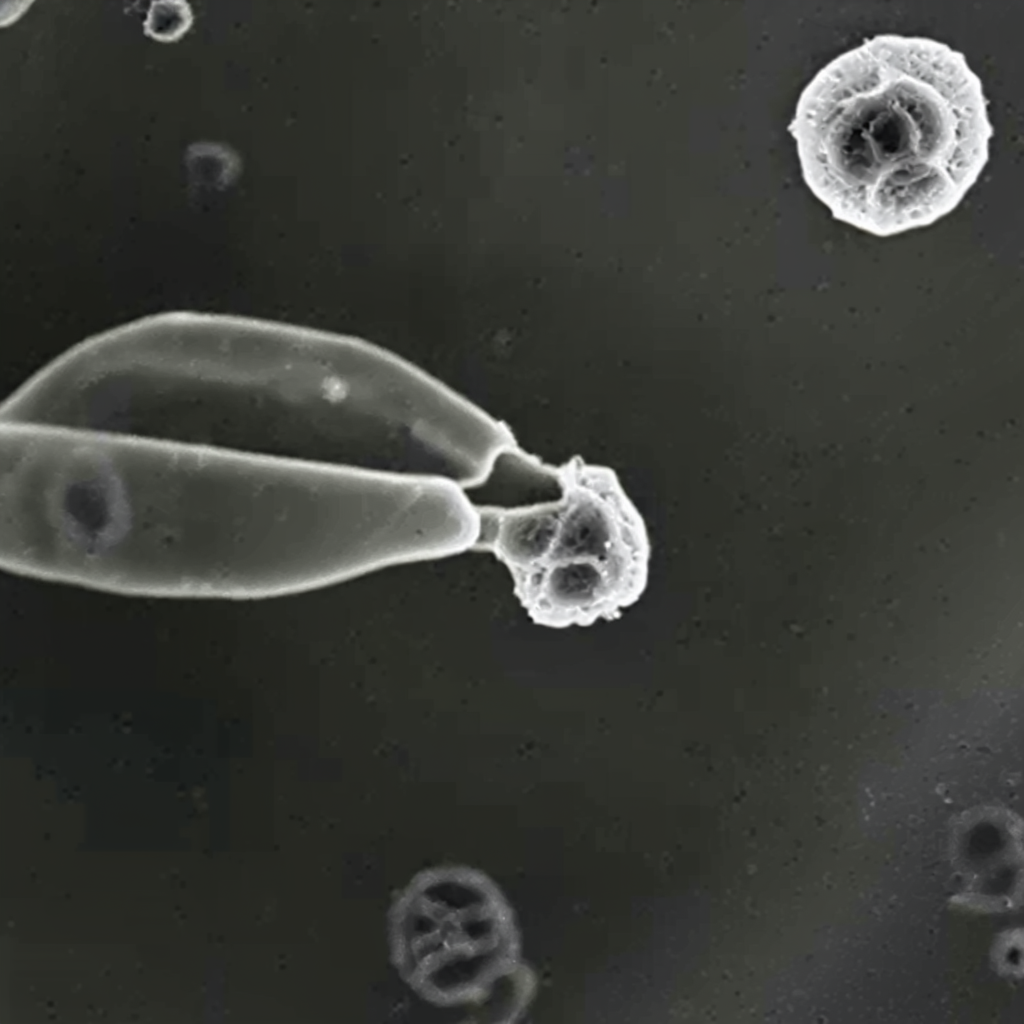 |
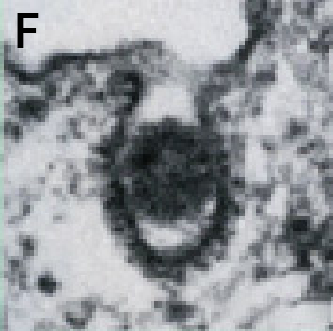
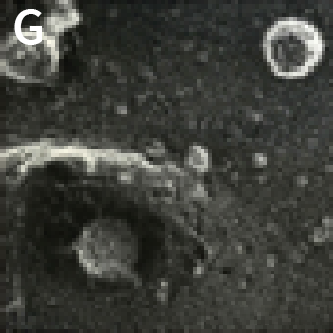
Figure 2.
(A) Structure of Influenza A virions from reference 1.
(B) Norwalk virus showing aggregation from reference 3.
(C) Fijivirus core particle from reference 2.
(D) Negatively stained mycoreovirus particle from reference 2.
(E) Negatively stained double shelled coltivirus particle from reference 2.
(F) Influenza A uptake into vesicle (CCP) from reference 4.
(G) Semliki Forest uptake into vesicle (invagination) from reference 4.
Results Summary
Overall, Midjourney’s image-to-image function appears best for preservation of style, while FLUX.1-dev’s is better for preservation of composition and arrangement. Playground’s lack of control with regards to how the model handles the reference image greatly limits the ability to evaluate its capabilities; all images were very distant from the reference. Denoise strength or image weight hyperparameters are critical for ensuring how strictly the reference image is followed. Finally, it may be helpful to run the prompt once without the initial image to see if the subject is within the model’s knowledge, ensuring an intelligent transformation.
Conclusion
Using life science images (e.g. in marketing) can enhance the visual appeal and interest of the content, increasing engagement from viewers. Generative AI brings the potential to remix and revisualize scientific imagery that is typically low-resolution, such as electron microscope images of virions, increasing their versatility. These outputs can be used when variations or higher quality revisualizations of existing images are needed. However, since diffusion models have become so advanced, it is often difficult (or impossible) to differentiate their output from real images. When using AI to create scientific visualizations, especially from existing references, it’s important to note the potential for data fabrication. AI-generated content should preferably be marked as such when used, so viewers do not misinterpret it as authentic data. This is particularly relevant when using open-source models such as FLUX, which do not have a limit on the similarity to the reference image that can be achieved.
References
- Burrell, C. J., Howard, C. R., & Murphy, F. A. (2017). Virion Structure and Composition. In Fenner and White’s Medical Virology (pp. 27–37). doi:10.1016/b978-0-12-375156-0.00003-5
- King, A. M. Q., Adams, M. J., Carstens, E. B., & Lefkowitz, E. J. (Eds.). (2012). Virus taxonomy: Classification and nomenclature of viruses. Ninth report of the International Committee on Taxonomy of Viruses. Elsevier.
- Teunis, P. F. M., Moe, C. L., Liu, P., Miller, S. E., Lindesmith, L., Baric, R. S., … Calderon, R. L. (2008). Norwalk virus: how infectious is it? Journal of Medical Virology, 80(8), 1468–1476. doi:10.1002/jmv.21237
- Yamauchi, Y., & Helenius, A. (2013). Virus entry at a glance. Journal of Cell Science, 126(Pt 6), 1289–1295. doi:10.1242/jcs.119685




