


Author: Nylah Williams, Human Biology major and Global Health minor, University of California, San Diego, Class of 2026
Key takeaways
- How MidJourney performs in generating scientific and laboratory imagery, including strengths (basic lab equipment, some cell types) and weaknesses (pipettes, molecular accuracy).
- Why representation matters: evidence of systemic bias in AI outputs, with default images of scientists skewing white and male, and requests for scientists of color often returning animated rather than photorealistic images.
- Practical insights on prompt design, version control, and platform differences (Discord vs. web) to improve image quality and mitigate, but not fully eliminate, biases.
- How collaborations with labs and institutions can supply authentic, diverse datasets to reduce bias and improve generative AI outputs.
Abstract
This project sought to address two key questions: First, can MidJourney accurately render complex scientific imagery and laboratory equipment? And second, does its output reflect systemic biases, particularly in the representation of scientists? To answer this question, we first sought to understand how Midjourney develops images and then do some real world testing. I documented the setup process, developed a prompting protocol, and tested a variety of lab and molecular prompts across different MidJourney versions while tracking generation time, image quality, and representation. The system reproduced some laboratory equipment with reasonable accuracy but struggled with finer details like pipettes and complex molecular structures. Prompt specificity improved image quality, yet biases were evident: when researcher demographics were left unspecified, the AI defaulted to white, male figures, and requests for people of color often produced animated rather than photorealistic images. These findings indicate that while MidJourney shows promise as a creative tool for scientific visualization, its accuracy and representational equity remain limited, highlighting the need for careful prompting and more diverse training data to improve its scientific and inclusive capabilities.
Introduction
MidJourney is a generative artificial intelligence (AI) image platform operated through Discord bot commands or web interface commands. It produces images in response to user-supplied text prompts, with output quality depending heavily on the specificity of those prompts and the training data underlying the model. MidJourney’s engine is built on large language and diffusion models trained on billions of image text pairs from publicly available, licensed, and web-scraped sources. It then converts text prompts into numerical vectors and iteratively refines random noise to synthesize four candidate images within minutes. Users can then choose an image to upscale for higher resolution, create variations, or further adjust styling through built-in commands such as “–v” for version control, “–stylize” for artistic effects, and other refinement tools.
Access to MidJourney is available either through its Discord integration or the standalone web app. Because MidJourney is increasingly used in educational, scientific, and communication contexts, it’s critical to test how well it handles technical accuracy and representation. Evaluating both performance and bias not only highlights current limitations but also guides improvements for more reliable and inclusive scientific visualization.
Technically, its reliance on probabilistic pattern-matching, rather than domain-specific knowledge, makes testing especially important in fields like science where precision is non-negotiable. These challenges highlight the importance of examining how AI systems generate scientific imagery and whose perspectives they reflect. These shortcomings are not merely technical; they also reveal how cultural and historical patterns are embedded in training data.
Attempts to specify scientists of color often result in less realistic, sometimes cartoon-like portrayals, suggesting that the model has been trained on a visual corpus where certain identities are underrepresented or stereotyped. Such representational gaps underscore a broader issue: AI systems not only mirror existing inequities but can also amplify them if left unexamined. It also prompts me to inspect where this agent is sourcing its data to uncover why this issue is occurring.
Methods
To evaluate MidJourney’s capacity for scientific visualization, I tested both Discord and the desktop versions to make accurate comparisons on its performance. Prompt experiments focused on two categories: (a) photographic images of people in laboratory settings and (b) molecular or cellular illustrations.
| Interaction | Prompt (Exact) | MidJourney Version Employed | Key Outcome / Observation |
1 | “Imagine a researcher creating a PCR gel” | Default | Needed 3 generations of refining and upscaling; final image acceptable but generic. |
2 | “Imagine a Black female researcher using a centrifuge in a well-lit lab” | Default | Centrifuge was refined after upscaling, but the lab remained dark despite “well-lit” request. |
3 | “Imagine a Mexican male researcher separating supernatant from pellet after centrifugation” | Default | Produced the brightest, most accurate lab scene of the series. |
4 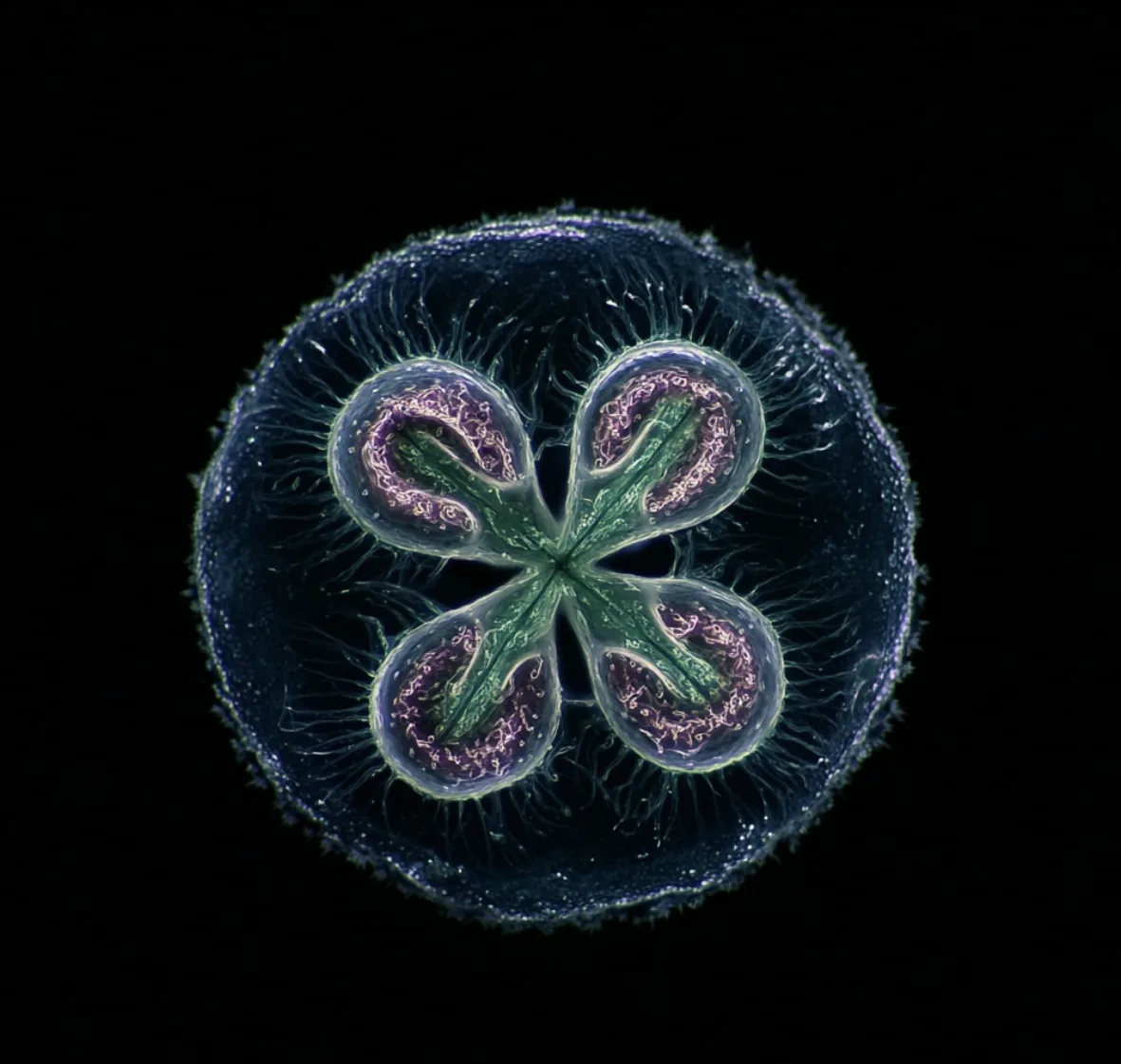 | “Mitosis in prophase” | v5 | After refinement, the image moderately got better but still needed to be stylized. |
5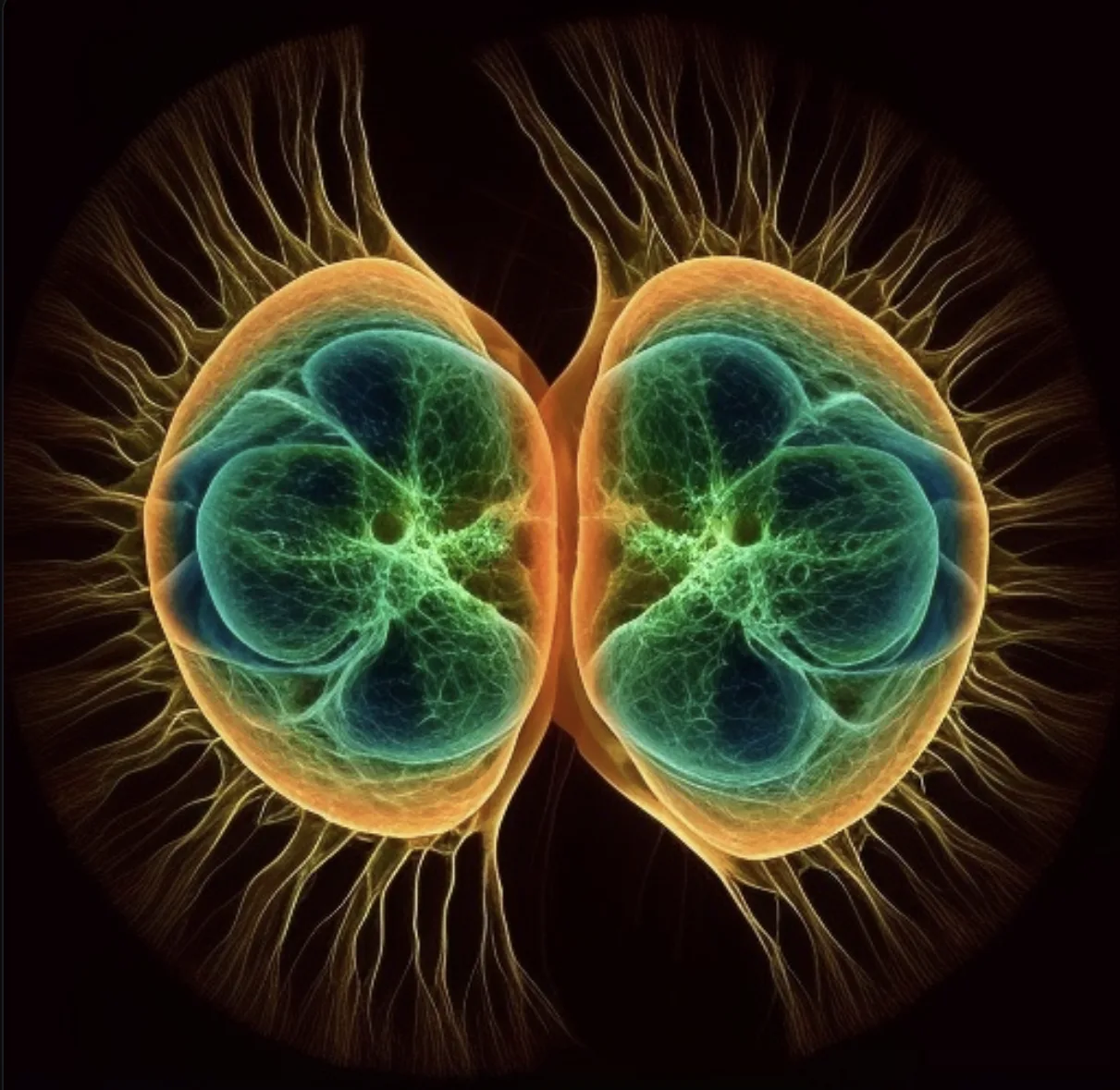 | “Mitosis in prophase” | v4 | Output unexpectedly worse than v5—less biological fidelity. |
6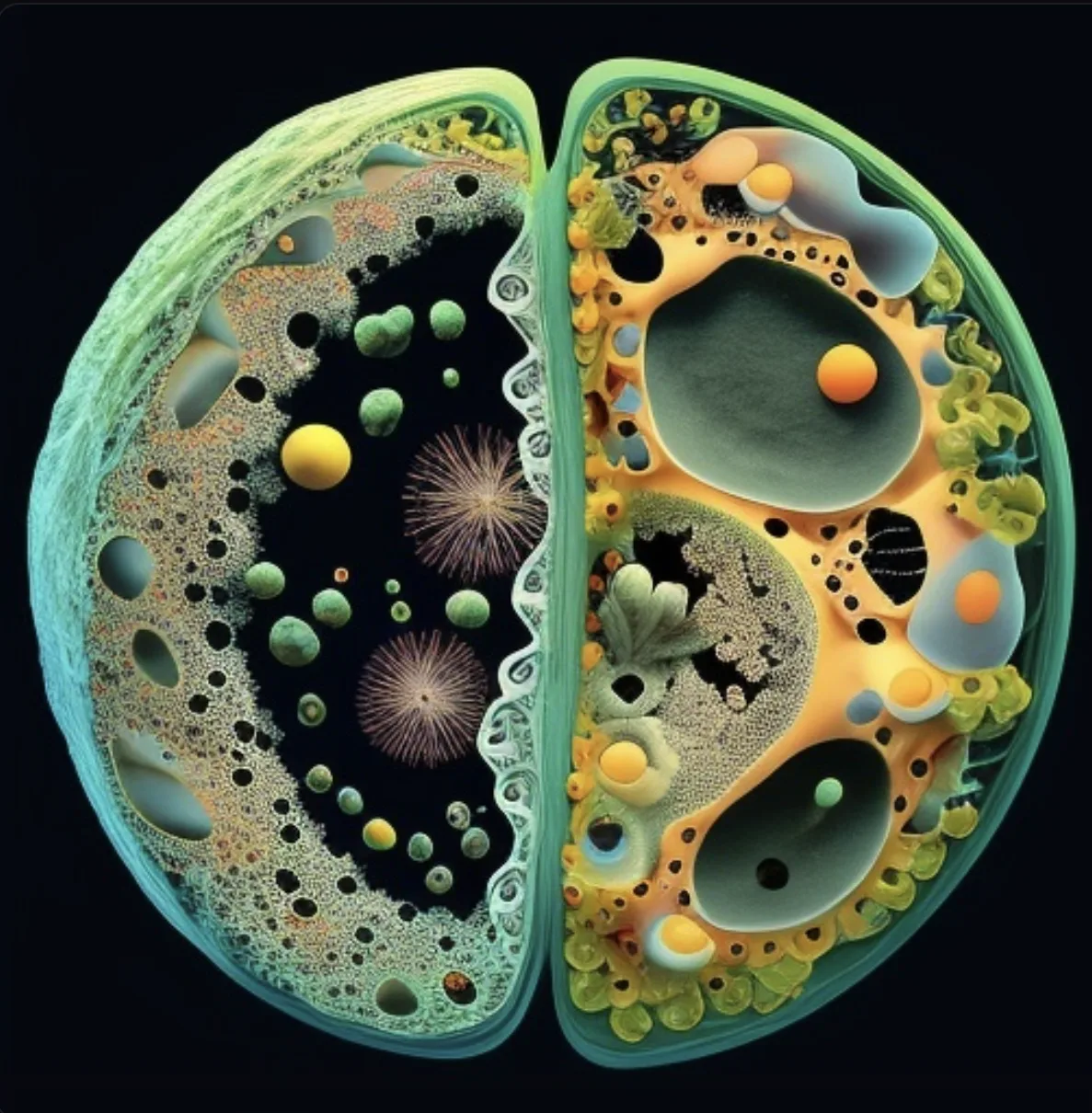 | “Eukaryotic cell” | v4 | Generated two unrelated cells, illustrating version-dependent inconsistency. |
7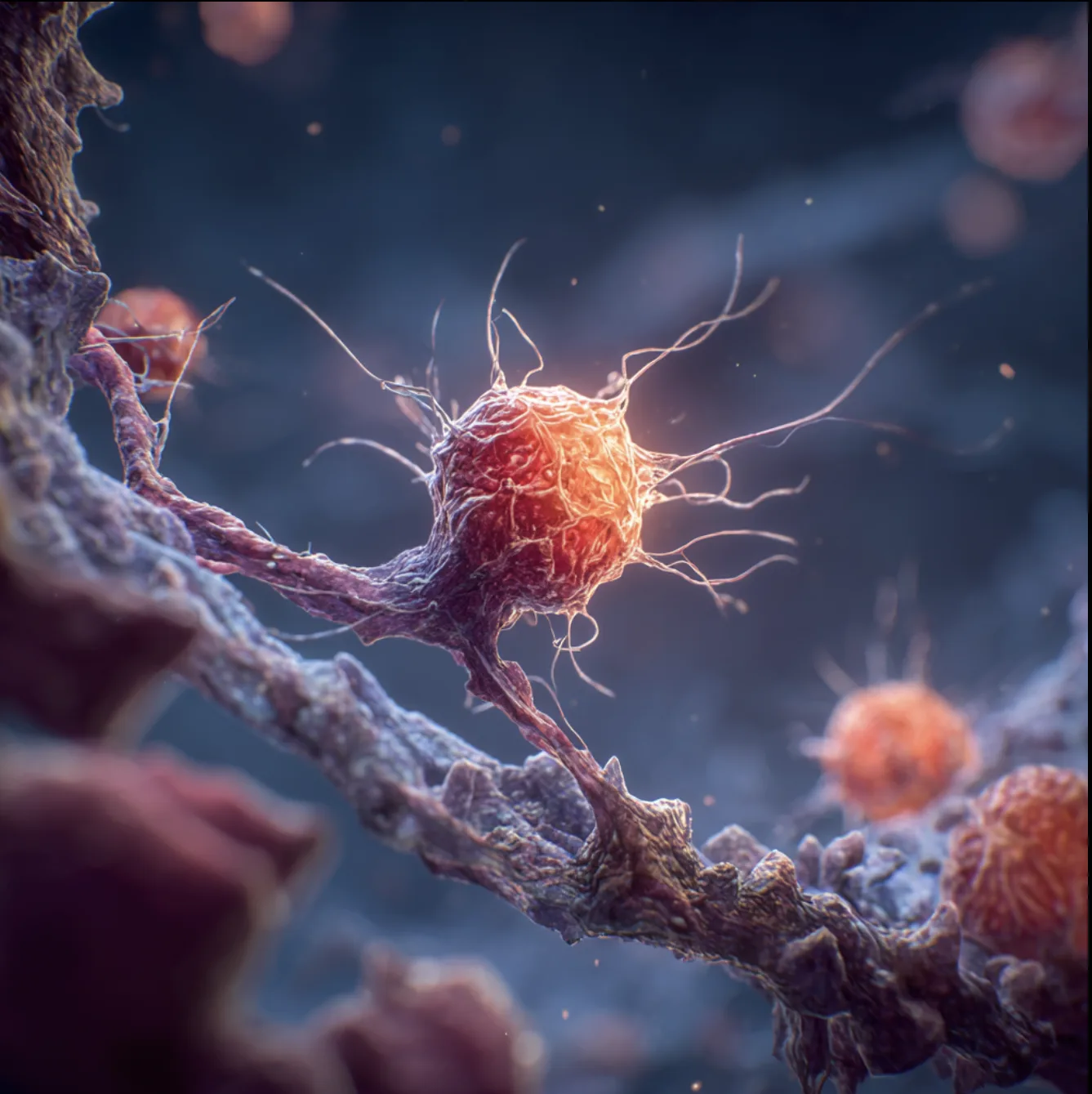 | “Macrophage removing dead cells” | Discord (latest version) | High-quality, realistic depiction of a macrophage, suggesting strong representation of this cell type. |
8 | “Imagine her as a life scientist” (using a reference photo) | Discord | Returned only animated images despite a photorealistic request. |
9 | Same as above with a “video” prompt | Default | Produced a better, more lifelike result than static runs. |
Results
Question 1: Can MidJourney accurately render complex scientific imagery and laboratory equipment?
My testing revealed both the creative potential and the limitations of MidJourney as a scientific visualization tool. With carefully written prompts, the platform generated convincing depictions of laboratory equipment, but it consistently struggled to create realistic pipettes and to render laboratory environments with accurate lighting. Molecular and cellular images varied by model version: Version 5 produced moderately accurate mitosis images, while Version 4 unexpectedly performed worse when it was expected to perform better with creating molecular images.
For example, the prompt “eukaryotic cell” in v4 produced two disjointed cells, yet a Discord-based prompt for “macrophage removing dead cells” yielded a highly realistic and detailed image, suggesting some cell types are better represented in the training data than others. In contrast, MidJourney rendered common laboratory equipment such as PCR plates and centrifuges relatively well, though it struggled to create accurate pipettes.
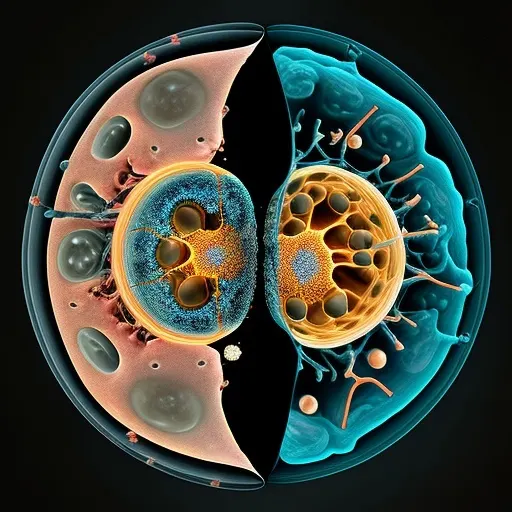 vs
vs
“Imagine a eukaryote split in half showing its structures” and “Macrophage removing dead cells”
Question 2: Does image output reflect systemic biases, particularly in the representation of scientists?
The most striking finding involved bias and representation: when researcher demographics were left unspecified, MidJourney almost invariably generated white, male figures, and prompts specifying people of color often produced animated or stylized results even when explicitly requesting “photorealistic” images. This pattern likely stems from the platform’s training data, which draws on a vast mix of publicly available and licensed images from the internet. Photorealistic images of scientists of color are comparatively rare so the training doesn’t have many realistic photos to go off of, while illustrated or “fan-art” depictions are more common, leading the model to associate descriptors like “Black female scientist” or “Mexican male researcher” with animated or artistic styles. Overall, MidJourney excels at rapidly creating striking, customizable visuals and can depict certain laboratory tools or specific cell types with surprising accuracy, but it remains inconsistent with complex molecular structures and struggles with equitable, photorealistic human representation underscoring the need for precise prompting, thoughtful version selection, and awareness of training-data biases when using it for scientific or educational purposes.
 vs
vs 
Q3: How did MidJourney’s Discord interface compare to the web version in terms of usability and performance?
I also compared Discord’s interface with the web version and found Discord slightly slower and less intuitive, particularly when using the “/describe” feature or reference photos. Timing also differed with experience, whereby the Discord interface proved slower and less intuitive than the web version, particularly when using the “/describe” command or reference-photo workflows.
CONCLUSION
This evaluation highlights MidJourney’s promise as a rapid scientific visualization tool but also exposes a significant limitations. While MidJourney effectively visualizes certain laboratory equipment and cell types, its inconsistent performance across model versions and training data gaps limit its reliability as a scientific imaging tool, particularly for pipettes and accurate laboratory lighting. Moreover, its training data lacks sufficient, high-quality images of scientists of color, leading to biased outputs such as default white, male figures or animated renderings when prompts specify people of color. These challenges highlight the importance of examining how AI systems generate scientific imagery and whose perspectives they reflect. These shortcomings are not merely technical; they also reveal how cultural and historical patterns are embedded in training data. Attempts to specify scientists of color often result in less realistic, sometimes cartoon-like portrayals, suggesting that the model has been trained on a visual corpus where certain identities are underrepresented or stereotyped. Such representational gaps underscore a broader issue: AI systems not only mirror existing inequities but can also amplify them if left unexamined. It also prompts me to inspect where this agent is sourcing its data to uncover why this issue is occurring. Due to how Midjourney was trained, mainly on artistic and stylized images rather than real-world scientific references, it struggles to accurately depict realistic, well-lit laboratory environments. The model tends to favor dramatic, cinematic aesthetics with heavy shadows and colored lighting instead of the flat, fluorescent lighting typical in labs. This training bias also affects how it renders scientific details, meaning it can create some molecular or cellular imagery fairly well but often lacks accuracy or consistency with real lab settings.
Building Inclusive Training Sets: Partnering with Labs for Real Diversity in Midjourney Images
Generative AI can only reflect the diversity present in its training set, addressing this gap will require more than better prompting. Future efforts should focus on curating and contributing ethically sourced, high-resolution photos of diverse scientists in authentic lab settings; partnering with universities, research institutions, and professional societies to license or create such images; and implementing improved labeling or weighting so these examples have meaningful influence during training. Transparency about dataset composition and third-party audits could further guide these improvements. Open questions remain around how to collect and share inclusive data responsibly, what incentives can support large-scale contributions, and whether fine-tuning or targeted data augmentation might mitigate bias without full retraining. Tackling these challenges is essential if MidJourney and similar platforms are to provide scientifically accurate and truly representative images for education and communication. Overall, MidJourney excels at rapidly creating striking, customizable visuals and can depict certain laboratory tools or specific cell types with surprising accuracy, but it remains inconsistent with complex molecular structures and struggles with equitable, photorealistic human representation underscoring the need for precise prompting, thoughtful version selection, and awareness of training-data biases when using it for scientific or educational purposes.
